

Does fine-tuning have to be so complicated? Not really!
Understanding fine-tuning approaches available that are right for your use case and won't unnecessarily burn a whole in your budget

In my last issue, I discussed:
what is fine-tuning
some industry use cases
what you need to get started and
how to decide whether you need to fine-tune your models or not.
A quick recap:
AI teams are looking into fine-tuning open-source LLMs to get more control over their data and prompts, and to maintain intellectual property in-house. Other than this obvious reason, fine-tuning both open-source and closed-source models (like OpenAI) also promises better performance on your data and use cases, custom tonality, and reduction in cost (if you train a smaller model to perform tasks at the same level as a larger model).
Read more here - https://snigdhasharma.substack.com/p/fine-tuning-llms-your-blueprint-for?r=1v8hnm
Need assistance in figuring out how and where to leverage AI in your business? Reach out on LinkedIn for a discussion.
In this issue:
I get a bit more technical to understand what the fine-tuning jargon floating around the web actually means for a layman and how AI Experts decide which fine-tuning technique would be the best suited for your use case. So, here we go…
Types of fine-tuning
Task-Specific Fine-tuning
Imagine you have a pre-trained language model which is trained on general text. This model can summarize any text, try to answer general questions, but it might not perform as well if you ask it to extract custom entities like product names and their categories from a catalog of an e-commerce website with necessary precision.
That requires a model that has ‘seen’ that sort of task examples and understands how to categorize these custom products. We usually do this by feeding several such examples consisting of the input text from which these entities have to be extracted, asking the model to take a first shot at the task and then ‘correcting’ it if necessary by comparing it to human annotated outputs.
Data-Specific Fine-tuning:
Let's again start from a pre-trained model on a massive dataset of general text. This model can be used for various tasks, but it might not understand the lingo of a specific domain, like finance or medicine. It might understand common terminology that is out there on the web and was luckily captured in the initial data that model was trained on. But it might not understand nuances and subtle hidden meanings or differences between the context in the usage of such domain related terms. In one of the projects that I worked on, we clearly needed a fine-tuned model to understand the context behind domain terminologies to further perform downstream tasks, without which the model seemed ‘lost’ in the superficial aspects of the said terms.
Here, fine-tuning involves using the pre-trained model as a starting point and then training it on your specific data (e.g., financial reports or medical journals). This way, the model leverages its existing knowledge of language while adapting to the new domain's terminology and vocabulary.
So what does an AI Expert do to fine-tune a model?
A model consists of a complex structure of numbers called weights. These weights are arranged in multiple layers (a bit simplistic view, but enough to understand the concepts below). These weights and relationships between these weights and your data is what determines how the model responds to your data. Here are some technical ways to adapt a large model to your task or domain:
1. Full Fine-tuning:
You take your pre-trained model and train it on your entire dataset for the specific task/domain. All the layers of the model are involved in the training process. This is generally used to train a model on your specific domain data - for multiple downstream tasks.
* Benefits: This method can lead to the best possible performance on the target task/domain, especially if the pre-trained model and your data are closely aligned.
* Drawbacks: It requires the most computational resources and time for training. Additionally, there's a risk of overfitting, where the model performs well on the training data but poorly on unseen data. This happens more often than you’d think, especially in an attempt to showcase better accuracy numbers on a test data that is not even representative of your entire dataset.
2. Partial Fine-tuning (Layer Freezing):
Here, you only train a specific subset of layers in the pre-trained model. The initial layers, which capture general language understanding, are often not changed at all, while the later layers are fine-tuned on your specific task/domain data.
* Benefits: This approach is a good balance between accuracy and efficiency. It leverages the pre-trained knowledge while adapting to the specific task/domain. It also reduces the risk of overfitting compared to full fine-tuning.
* Drawbacks: It might not achieve the absolute best performance as compared to full fine-tuning, especially if the task/domain is very different from the original training data of the pre-trained model.
3. Adapter Modules:
Parameter efficient fine-tuning (PEFT) method involves adding new additional layers (also called adapter modules) on top of the pre-trained model. These adapter modules are specifically trained on the target task/data. The pre-trained model itself remains unchanged. Total number of parameters ‘tuned’ to your data are much less than the previous two approaches.
* Benefits: This approach is particularly efficient when dealing with limited data for the target task. The adapter modules are much smaller than the entire model, requiring less training data and computational resources. This also reduces overfitting risk.
* Drawbacks: Adapter modules might not capture complex relationships between features as effectively as fine-tuning existing layers.
4. Multi-task Fine-tuning:
This approach involves training the model on multiple learning tasks simultaneously. Your dataset might encompass data for sentiment analysis, topic classification, and question answering, and the model learns to perform all these tasks during the fine-tuning process.
* Benefits: This method can be useful when you have data for multiple related tasks but not enough data for each individual task. It promotes knowledge transfer between tasks and can potentially improve performance on all tasks.
* Drawbacks: Designing the training process for multiple tasks can be complex. Additionally, the model might not achieve the same level of accuracy on each individual task as compared to training separate models for each task.
The best fine-tuning method for your specific scenario depends on a lot of factors including but not limited to: the size and complexity of your dataset, the similarity between the pre-trained model's domain and your target task, and the available computational and development resources. It's often a good idea to do a deep analysis of your task, data and performance with a foundational model (pre-trained model like ChatGPT). You might also need to experiment with different approaches to see what yields the best results in some scenarios.
Let’s get technical: Fine-Tuning Algorithms
Here's a breakdown of some paradigms in fine-tuning algorithms. Each paradigm further has many adaptations and optimized algorithms to choose from.
PEFT (Parameter-Efficient Fine-Tuning):
Summary: A technique for fine-tuning LLMs with significantly reduced memory requirements compared to full fine-tuning. It utilizes algorithms like Low-Rank Adapters (LoRA) to achieve this memory efficiency.
Benefits:
Requires less memory, allowing fine-tuning of larger models on limited hardware resources.
Potentially faster training times due to reduced memory usage.
Lesser data requirement as compared to partial or full layer fine training
Drawbacks:
Performance might not always match full fine-tuning, especially for complex tasks.
Prompt Tuning:
Summary: Prompt tuning guides language models by adjusting initial prompts crafted by users into a set of numbers (called prompt embeddings) and refining these embeddings (list of numerical parameters) through back-propagation to learn from labeled examples. Unlike fine-tuning, which modifies the entire model, prompt tuning updates newly added prompt tokens while keeping the pre-trained model's weights fixed. So it can be thought of as similar to PEFT, with a difference that the additional parameters are guided by the user with a prompt written in natural language.
Benefits:
Enhanced Performance: Combining fine-tuning and prompt engineering improves language model performance.
Additional Input: Soft prompts generated by AI offer supplementary context for better output generation.
This can significantly reduce the number of examples (and hence tokens) in your prompt by tuning your prompt with a much larger number of examples.
Drawbacks:
Reduced Explainability: Soft prompts, being a set of numeric values, lack human readability, diminishing the model's explainability.
Dependency on AI: The effectiveness of prompt tuning relies on the accuracy and relevance of AI-generated soft prompts.
Distributed Training Techniques
Summary: A distributed training technique that partitions the model parameters, gradients, and/or optimizer states across multiple GPUs or machines. This allows training of very large models (up to 1 Trillion parameters) that wouldn't fit on a single GPU. Each ‘slice’ of the model is then stored and trained on a different machine. Examples include Fully Sharded Data Parallel (FSDP), ZeRO (Zero Redundancy Optimizer)
Benefits:
Enables training of massive LLMs by overcoming memory limitations of single GPUs.
Can improve training speed by leveraging multiple processing units.
Complex setup might not be necessary for smaller models that fit on a single GPU.
Drawbacks:
Requires expertise in distributed training and potentially complex setup.
Sometimes, you can even combine these techniques to get the most out of your models.
Quicker alternatives to fine-tuning
This probably goes without saying, but before getting lost in the deep mess of fine-tuning your models - be sure to evaluate much simpler techniques - which suffice for most use cases.
RAG (Retrieval-Augmented Generation):
Summary: RAG retrieves relevant passages from an external knowledge base in response to a prompt or query. It then uses these retrieved passages along with the prompt to generate a more informative and factually accurate response.
Benefits:
Improves factual accuracy and grounding, especially for tasks requiring real-world knowledge.
Can be more efficient than fine-tuning for tasks where access to relevant information exists.
Drawbacks:
Requires building and maintaining a high-quality knowledge base relevant to the task.
Performance depends on the quality and relevance of retrieved passages.
Prompting
Summary: An approach where you provide the LLM with a carefully crafted prompt or instruction that guides it towards the desired output format or task. This can be effective for specific tasks without requiring extensive fine-tuning of the entire model.
Benefits:
Simpler and faster to implement compared to fine-tuning.
Can be effective for tasks where specific instructions or formats are well-defined.
Drawbacks:
Performance might not be as good as fine-tuning for highly complex tasks.
Requires crafting effective prompts that may involve a lot of experimentation and expertise.
For some ideological advice on how to think about crafting better prompt instead of mindlessly trying out multiple approaches - read my article here - https://snigdhasharma.substack.com/p/are-you-engineering-your-prompts
How to choose?
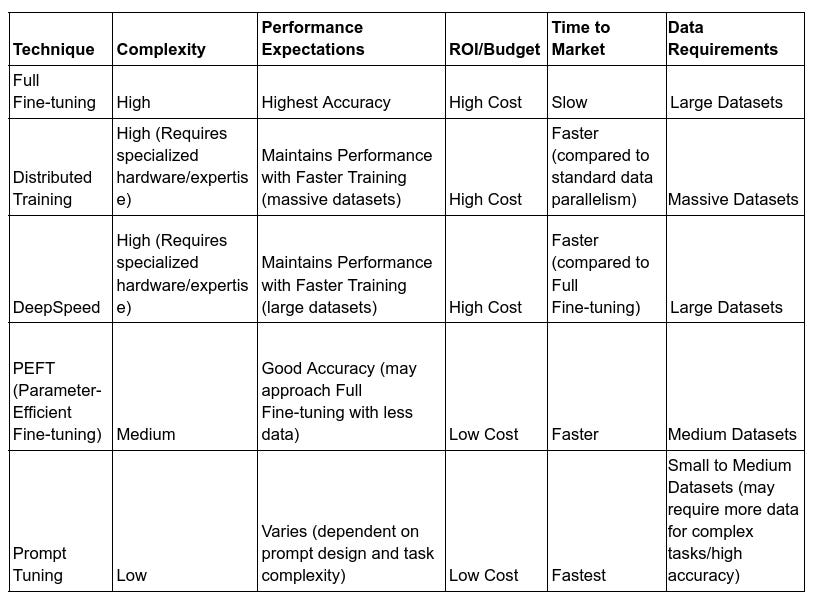
Choosing the Winner:
The ideal technique depends on your project. Consider the trade-offs between complexity, performance, budget, and time-to-market.
For high-accuracy tasks with ample resources, full fine-tuning might be the best choice.
For resource-constrained projects, PEFT or prompt tuning offer attractive options.
DeepSpeed and FSDP shine when dealing with massive datasets and tight deadlines.
Stay tuned! Next up I will discuss how to ensure maintenance for your Generative AI use cases. Doesn’t matter if you are fine-tuning or just using well defined prompts - generative AI can be hard to tame for production use cases. It’s important to know all the aspects that go into turning a generative AI project into a production success after your initial development phase.
What’s Next?
Comment below to request coverage for any particular aspect that is not mentioned here.
Hosting: How to decide where to host your fine-tuned LLMs or open-source foundational models?
Evaluation: How to evaluate LLMs for your use cases?
Monitoring: How to monitor responses from LLMs? Also, what all needs to be monitored and how do you make use of this information?
Error Mitigation: What to do when LLM gives an erroneous response?
Explainability: LLMs can look like a black box that you can’t seem to see the constituents of. But how to interpret and debug your LLM responses?
Maintenance: of your fine-tuned LLMs or your prompts over time when your data and priorities keep evolving.
Need assistance in figuring out how and where to leverage AI in your business? Reach out on LinkedIn for a discussion.