

How to Balance Randomness and Determinism in your Generative AI projects?
Some actionable steps to consider for your generative AI pipelines

Determinism of software products has served us for so long, we can’t completely let go of the nervousness that ensues when you have a generative AI feature deployed that can generate text without ‘checking in with the legal team’ and run code on the fly.
And yet, here we are, in the generative AI era, deploying models that we don’t have much control on and yet everyone seems okay with it - users, businesses, hell even that legal team of yours! Times have changed, even more so in the last couple of years, and so have everyone’s expectations. If you don’t keep up with these expectations, someone else would. But how to responsibly balance determinism and randomness for generative AI pipelines? Read ahead!
To understand where LLMs get their randomness from - read The Deception of Consistency
Where Determinism Shines:
Accuracy in Critical Tasks: Imagine a customer booking a flight. If the departure time keeps changing, it creates confusion and frustration. Deterministic logic ensures consistent information about flights, prices, product descriptions and availabilities etc.
Following Established Procedures: For tasks with clear guidelines, like resetting a password or processing a return, determinism ensures the exact steps are followed every time, avoiding errors or missed steps.
Building Trust: Consistent and reliable answers build trust with users. They know they'll get the same information every time they ask a question.
However, Non-Determinism (Randomness) Can Be Helpful Too:
Engaging Conversation: Interactions don’t have to sound robotic! Introducing variation in responses makes interactions more natural and engaging for users. Just ensure the core information stays consistent.
Handling Open-Ended Questions: For open-ended questions that don't have one right answer, non-deterministic systems can provide multiple perspectives or creative solutions, offering users a broader range of options.
Personalization: Responses can be personalized based on user history or preferences, creating a more tailored experience. However, it's important to avoid giving conflicting advice due to over-personalization.
The Takeaway:
It's a balance! Determinism ensures accuracy and reliability in critical areas, while non-determinism can enhance user experience and handle open-ended situations.
Need help in figuring out the right balance for your use case? Reach out on LinkedIn today for consultations and/or development help!
Great! Now let’s take a look at some actionable steps to manage randomness in LLMs so you can have that cake and eat it too!
Managing Randomness in GenAI production pipelines
Managing randomness in production use cases where at least some level of consistency in outputs is crucial, involves several strategies to balance creativity with reliability. Here’s how to tackle randomness effectively:
1. Set Realistic Expectations
- User Education: Clearly communicate to users that LLMs are advanced tools but not perfect replacements for human judgment. Emphasize that some variability in responses is expected, even with low temperature settings. Look at the screenshot below and see how even OpenAI adds those little disclaimers right below the chat input (“ChatGPT can make mistakes. Check important info.”)
- Guidelines: Offer guidelines on how to interact with the model to achieve the best results, such as framing clear and specific prompts.
2. Controlled Parameters:
- Set Boundaries: Set parameters for randomness such as temperature and top p values. Experiment to find settings that balance creativity with consistency for your specific use case.
- Regular Adjustment: Monitor and adjust these parameters based on user feedback and performance to maintain desired output quality.
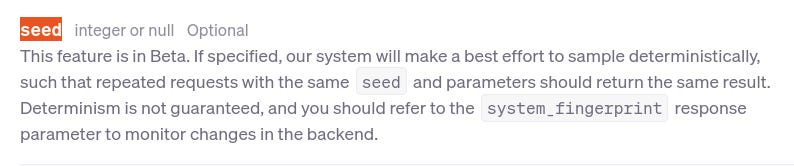
- Seed: Some vendors like OpenAI provide other parameters like ‘seed’ to help return mostly deterministic outputs. You can even track system_fingerprint field in response to check if the configuration has changed or not.
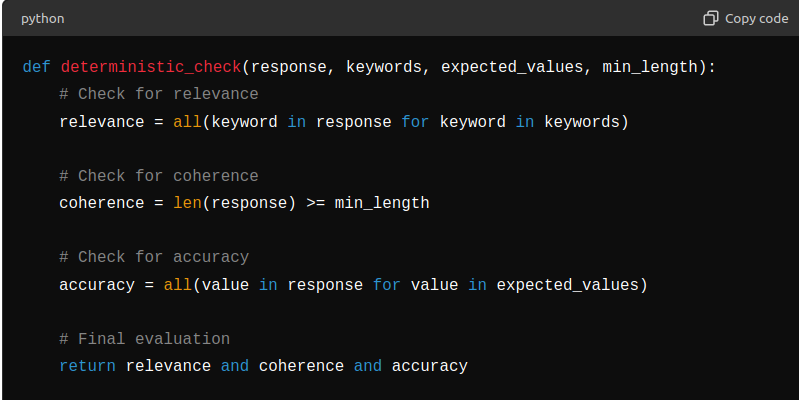
3. Deterministic Checks
- Validation Rules: Implement deterministic checks to evaluate whether the generated responses meet predefined criteria, such as relevance, accuracy, and coherence. (Some basic toy implementation in the image below)
- Automation: Use automated scripts to perform these checks on a large scale, ensuring consistency across all outputs.
- Fallback Mechanisms: Establish fallback mechanisms to handle outputs that fail deterministic checks, such as generating a new response or triggering human review.
4. Ensemble Approaches:
- Multiple Models: Use ensemble methods where outputs from multiple models are combined or selected based on predefined criteria. This can mitigate the impact of individual model randomness.
- Weighted Averaging: Use weighted averaging or voting mechanisms to decide on the final output, reducing the impact of outliers.
- Bias Reduction: Ensemble methods help in reducing bias and increasing robustness, as they aggregate diverse perspectives from different models.
5. Cache Results
- Caching Strategy: Cache responses that meet the quality criteria defined by deterministic checks. This ensures that high-quality responses are reused, enhancing consistency.
- Version Control: Implement version control for cached responses to manage updates and improvements over time.
- Efficiency: Use caching to reduce computational load and latency, providing quicker responses to users.
6. Task Segmentation
- Divide and Conquer: Break down complex tasks into smaller, manageable sub-tasks. This reduces the scope for randomness to impact the overall output.
- Sequential Processing: Process each sub-task sequentially, ensuring that each step meets quality standards before proceeding to the next.
- Modular Design: Design tasks in a modular fashion so that each module can be individually optimized and refined.
7. Contextual Prompting
- Rich Prompts: Provide detailed and context-rich prompts to guide the LLM towards desired responses. The more context the model has, the better it can tailor its output.
- Example-Driven: Include examples in prompts to illustrate the type of response expected.
- Prompt Engineering: Continuously refine and optimize prompts based on the model’s performance and feedback.
8. Fine-tuning
- Domain-Specific Training: Fine-tune the LLM on domain-specific data to improve its relevance and accuracy for particular tasks.
- Specialization: Tailor the model to specific tasks or industries, enhancing its ability to provide consistent and high-quality outputs.
- Iteration: Regularly update and fine-tune the model to adapt to new information and changing requirements.
9. Interpretability
- Insight Tools: Use interpretability tools to understand the model’s decision-making process and gain insights into its behavior.
- Debugging: Identify and address issues or biases in the model’s responses through detailed analysis.
- Transparency: Enhance transparency by explaining how and why the model generates certain responses, building user trust.
10. Human-in-the-Loop
- Quality Assurance: Integrate human oversight to review and refine outputs, ensuring they meet high standards of quality and consistency.
- Hybrid Approach: Combine AI capabilities with human expertise to handle complex or sensitive tasks effectively.
- Feedback Loop: Use human feedback to continuously improve the model’s performance and accuracy.
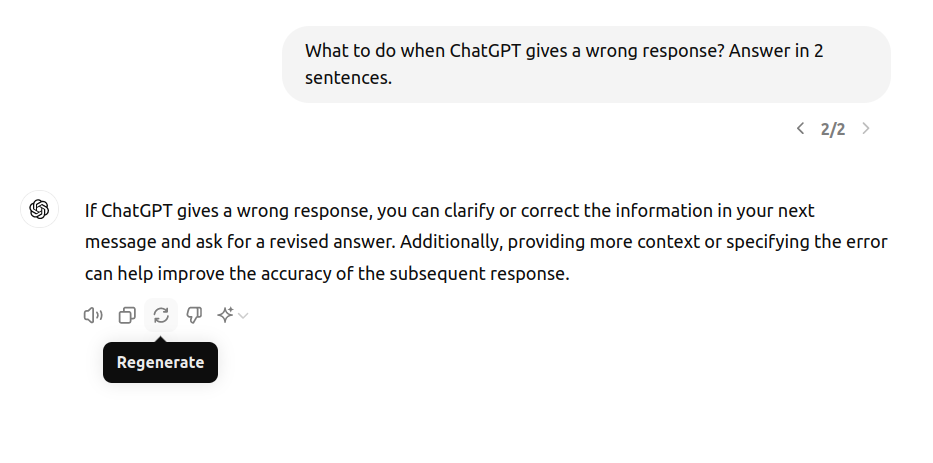
11. Allow Retries
- Retry Options: Design your product to allow users to request another response if the initial one doesn’t meet their expectations.
- Transparency: Inform users about the option to retry and encourage them to use it when necessary and take the best or the most common response.
12. Adaptive Learning
- Continuous Learning: Implement adaptive learning techniques to update and refine the model based on ongoing performance and user feedback.
- Dynamic Adjustment: Adjust parameters and strategies dynamically in response to observed trends and issues.
- Scalability: Ensure that your approach can scale and adapt to evolving requirements and data.
13. Error Analysis
- Regular Reviews: Regularly analyze errors and inconsistencies in the model’s responses.
- Pattern Identification: Identify patterns and common issues to target areas for improvement.
- Proactive Refinement: Use error analysis to proactively refine the model and reduce future inconsistencies.
Need help in figuring out which one of these applies to your use case? Reach out on LinkedIn today for consultations and/or development help!
By implementing these strategies, organizations can effectively harness the benefits of randomness in LLMs while ensuring that outputs meet the consistency and quality standards required for production use cases. This approach balances innovation with reliability, enhancing the overall utility and user experience of AI-driven applications.
Uncertainty in artificial intelligence manifests at multiple levels, including environmental randomness, measurement noise, incomplete information, uncertainty in model predictions, uncertainty in human decision-making, uncertainty in technological development, and uncertainty in the responses of dialogue systems.