

Training an LLM: No-jargon understanding of LLM architectures and capabilities
An intuitive explanation of architectures for language models in NLP and why one of them shines brightly in the LLM world today.

There are some mad wars going on in the LLM world - wars around whose model is the ‘best’, which one can write a poem better, which can solve a math puzzle, which has the most users, what data was used to train them and what privacy rules were compromised in doing so.
And with so many questions around data privacy and making LLMs understand your custom enterprise data - without giving up on privacy, many teams are now looking to train (or fine-tune) their own Language Models - small and large. And with that, many developers suddenly find themselves deep down in a rabbit hole of understanding the architectures behind these giant models.
This article aims to answer one common question around the basics of LLM training. Understanding the basic architecture of LLMs allows you to digest everything that follows in the training process.
I’ll try to explain the concepts in layman terms as much as possible - so you can grasp the intuition behind choosing language model architectures. But if you have any further questions, feel free to comment below!
Language model architectures
It's 2024, and the AI world is buzzing with chatter about large language models. All they do is take in some text and blurt out some more text, right?
And like people, they can follow 3 approaches of blurting out this new text:
Take in the input, understand and internalize it, think deeply and then say exactly what is needed. Like people who generally pause for 2 min (seems like an eternity sometimes!) and then speak.
Just go with the flow and start speaking already, the answer would flow by itself. Just like a verbose friend who tries to stay on topic, thinks loudly and somewhere along the whole conversation - manages to answer the other person’s question.
And there are some who would just take in the input, internalize it and not say anything at all!
Let’s get a bit technical now?
Encoder-Only: Type C
First let’s understand the encoder-only models – the introverts of the AI world! These quiet geniuses are like that friend who's always observing, processing, and understanding, but rarely speaks up. No output, no chit-chat, just pure, unadulterated understanding. It's like they're playing an endless game of "I Spy" but never actually telling you what they've spied on. These models excel at tasks like sentiment analysis or text classification – they're the strong, silent types who can read a room (or a sentence) better than most humans. So next time you want a model that can do all that understanding for you and leave the talking to the pros, tip your hat to the encoder-only architecture – proving that sometimes, it's not about what you say, but what you understand.
Typical use cases involve text embeddings which can be used for many downstream tasks like classification, recommendations etc.
Decoder-Only: Type B
A decoder-only architecture is all about predicting the next token in a sequence, whether it's a word, a subword, or even a character.
Imagine you're playing a high-stakes game of "Complete the Sentence" with an AI. You start with "The quick brown..." and the model jumps in with "fox jumps over the lazy dog." That's essentially what a decoder-only model does, but on steroids. It's constantly asking itself, "Given everything I've seen so far, what's the most likely next token?"
But here's where it gets interesting. These models don't just memorize sequences – oh no, that would be far too simple. Instead, they learn to understand context, grasp nuances, and even pick up on the subtle art of sarcasm (well, sometimes). It's like they've developed a sixth sense for language, allowing them to generate coherent and contextually appropriate text that can sometimes leave us humans scratching our heads in amazement.
Most of the well-known foundational language models powering chatbot like systems use this architecture.
In image generation models, the text input is first encoded and then fed into decoder-only architectures to generate images based on the representation of our prompts. Sounds simple? Well, if you don’t mind AI adding kittens and flowers while generating image of “a cute robot” :D. (DALL-E-3 probably associates the word ‘cute‘ with kittens and flowers and adds these elements in the image generated with a prompt - “generate image for a cute robot“)

Picture by DALL-E-3
Encoder-Decoder: Type A
Now, let's take a moment to appreciate the encoder-decoder architecture. If decoder-only models are like solo artists, encoder-decoder models are more like a well-coordinated band.
The encoder is like the studious friend who takes meticulous notes during a lecture. It processes the input sequence and compresses it into a dense representation. The decoder then takes these notes and turns them into a beautiful symphony of the next set of words.
This architecture shines in tasks where there's a clear input-output relationship, like language translation or summarization. Kind of like having a personal interpreter who not only understands what you're saying but can also rephrase it in a way that your grandma would understand.
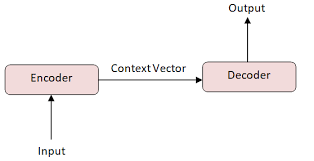
Medhabarve, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
The Great Decoder-Only Takeover: Reasons Behind the ‘Madness’
You might be wondering, "Aren't two steps better than one? Why aren’t we using the best of both worlds that Type A provides?" Why are most LLMs jumping on the decoder-only bandwagon? Let's break it down.
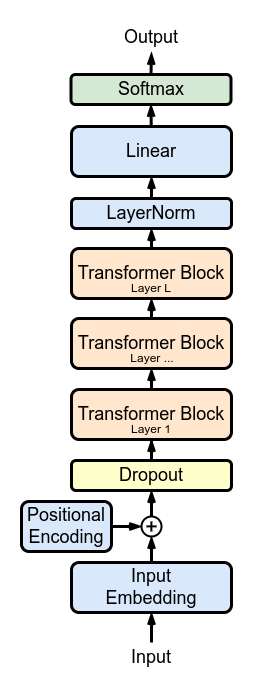
Marxav, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
a) Simplicity
Decoder-only architecture has truly embraced the "less is more" philosophy. By focusing solely on the task of next-token prediction, these models have streamlined their architecture to spark joy in AI researchers everywhere.
This simplicity isn't just aesthetic – it's functional. With fewer moving parts, there's less room for things to go wrong. It's like choosing a bicycle over a car for your daily commute. Sure, the car has more features, but the bike is easier to maintain, more efficient for short trips, and you don't have to worry about parallel parking!
b) Efficiency
In the world of AI, efficiency is king. Decoder-only models are the efficiency experts of the LLM world.
These models are particularly adept at learning from large amounts of unlabeled data. They don't need carefully curated datasets with input-output pairs. Instead, they can learn from the vast ocean of text available on the internet. They've developed a superpower to extract knowledge from the digital ether.
This efficiency translates to faster training times and lower computational costs. In a world where training a large language model can cost millions of dollars, this efficiency is not just nice to have – it's a game-changer.
c) Versatility
Remember that Swiss Army knife that could somehow fix anything from a loose screw to a broken nail? That's what decoder-only models are to the world of Natural Language Processing (NLP).
These models have shown remarkable ability to adapt to a wide range of tasks. Need a chatbot? Check. Want to summarize a long article? No problem. Looking for a model to generate code? You got it. It's like having a linguistic superhero that can swoop in to save the day, no matter what the language-related crisis might be.
This versatility comes from the model's ability to understand and generate language in a more general sense. Instead of being trained for specific tasks, these models learn to understand language as a whole, allowing them to tackle various challenges with surprising dexterity.
d) Scalability
Here's where things get really exciting. Decoder-only models have shown an almost magical ability to improve as they get larger. It's the secret to unlimited growth – the AI equivalent of finding the fountain of youth.
As we pump more parameters into these models (think billions and trillions), their performance keeps improving across a wide range of tasks. This scalability has led to the development of models like GPT-3 and its successors, which have shocked the world with their capabilities.
This scaling property is particularly attractive because it suggests a clear path forward: make the model bigger, and it gets better. It's a simple recipe for improvement that has driven much of the recent progress in AI. But how far can it really get? We’ll see.
Training your own LLM
If you're a company with stars in your eyes and dreams of creating your own LLM - what does this decoder-only trend mean for you? Let's break it down:
a) Lower Barrier to Entry
The simplicity of decoder-only architectures means you don't need to be Google or OpenAI to get into the LLM game. This architecture provides a more straightforward path to creating a competent language model without needing to navigate the complexities of encoder-decoder interactions and curating large and clean datasets.
b) Versatility for the Win
By choosing a decoder-only architecture, you're not pigeonholing yourself into a specific application. These models are like linguistic chameleons, adapting to various tasks with ease. This versatility could be a major advantage if you're not quite sure how you'll be using your model in the future.
c) Scaling Potential
The clear scaling path of decoder-only models is a roadmap for future improvements. As your resources grow, you have a straightforward way to enhance your model's performance.
d) Data Hunger Games
Here's the catch – these models are data gluttons. They need massive amounts of text to reach their full potential. Make sure you have access to large, high-quality datasets before you embark on this journey.
e) Computational Considerations
While decoder-only models are more efficient than their encoder-decoder counterparts, don't be fooled – training a large language model is still a Herculean task. You'll need some serious computational firepower. It's less "home computer" and more "small data center."
f) Ethical Considerations
As with any powerful AI technology, there are ethical considerations to keep in mind. These models can generate incredibly convincing text, which raises concerns about misinformation and misuse.
The Final Word (For Now)
As we wrap up this deep dive into the world of decoder-only architectures, one thing is clear – these models are not just a passing fad. They represent a fundamental shift in how we approach language understanding and generation in AI.
The simplicity, efficiency, versatility, and scalability of decoder-only models have made them the architecture of choice for many of the most impressive language models we see today. They've cracked the code to develop AI that can understand and generate human-like text.
But remember, the AI world moves at breakneck speed. While decoder-only models are the talk of the town right now, who knows what the future might hold? Perhaps we'll see a resurgence of encoder-decoder models, or maybe some entirely new architecture will come along and sweep us off our feet (and give us much awaited GPT-5 or PhD level intelligence ;) )
For now, though, if you're looking to dip your toes into the LLM waters, a decoder-only architecture is a pretty safe bet.
Whether you're an AI enthusiast, a tech company looking to join the LLM race, or just someone trying to understand why your chatbot sometimes sounds smarter than you, I hope this deep dive has given you some food for thought. Now go forth and decode the world of AI with confidence!
Need a team to develop you next LLM/SLM? Reach out on LinkedIn today for consultations and/or development!